Guia de Monitoramento e Métricas do OmniPGW
Integração com Prometheus e Monitoramento Operacional
por Omnitouch Network Services
Índice
- Visão Geral
- Endpoint de Métricas
- Métricas Disponíveis
- Configuração do Prometheus
- Painéis do Grafana
- Alertas
- Monitoramento de Performance
- Solução de Problemas com Métricas
Visão Geral
OmniPGW fornece duas abordagens complementares de monitoramento:
1. Interface Web em Tempo Real (coberta brevemente aqui, detalhada nos respectivos documentos da interface)
- Visualizador de sessão ao vivo
- Status do peer PFCP
- Conectividade do peer Diameter
- Inspeção de sessão individual
2. Métricas do Prometheus (foco principal deste documento)
- Tendências históricas e análise
- Alertas e notificações
- Métricas de performance
- Planejamento de capacidade
Este documento foca nas métricas do Prometheus. Para detalhes da Interface Web, veja:
Visão Geral das Métricas do Prometheus
OmniPGW expõe métricas compatíveis com Prometheus para monitoramento abrangente da saúde do sistema, performance e capacidade. Isso permite que as equipes de operações:
- Monitorar a Saúde do Sistema - Acompanhar sessões ativas, alocações e erros
- Planejamento de Capacidade - Compreender tendências de utilização de recursos
- Análise de Performance - Medir a latência de manipulação de mensagens
- Alertas - Notificação proativa de problemas
- Depuração - Identificar causas raízes de problemas
Arquitetura de Monitoramento
Endpoint de Métricas
Configuração
Ative as métricas em config/runtime.exs:
config :pgw_c,
metrics: %{
enabled: true,
ip_address: "0.0.0.0", # Vincular a todas as interfaces
port: 9090, # Porta HTTP
registry_poll_period_ms: 5_000 # Intervalo de polling
}
Acessando Métricas
Endpoint HTTP:
http://<omnipgw_ip>:<port>/metrics
Exemplo:
curl http://10.0.0.20:9090/metrics
Formato de Saída
As métricas são expostas no formato de texto do Prometheus:
# HELP teid_registry_count The number of TEID registered to sessions
# TYPE teid_registry_count gauge
teid_registry_count 150
# HELP address_registry_count The number of addresses registered to sessions
# TYPE address_registry_count gauge
address_registry_count 150
# HELP s5s8_inbound_messages_total The total number of messages received from S5/S8 peers
# TYPE s5s8_inbound_messages_total counter
s5s8_inbound_messages_total{message_type="create_session_request"} 1523
s5s8_inbound_messages_total{message_type="delete_session_request"} 1487
Métricas Disponíveis
OmniPGW expõe as seguintes categorias de métricas:
Métricas de Sessão
Contagens de Sessões Ativas:
| Nome da Métrica | Tipo | Descrição |
|---|---|---|
teid_registry_count | Gauge | Sessões S5/S8 ativas (contagem de TEID) |
seid_registry_count | Gauge | Sessões PFCP ativas (contagem de SEID) |
session_id_registry_count | Gauge | Sessões Gx ativas (contagem de Diameter Session-ID) |
session_registry_count | Gauge | Sessões ativas (pares IMSI, EBI) |
address_registry_count | Gauge | Endereços IP de UE alocados |
charging_id_registry_count | Gauge | IDs de cobrança ativos (veja Formato de CDR de Dados para registros de cobrança CDR) |
sxb_sequence_number_registry_count | Gauge | Respostas PFCP pendentes (aguardando resposta) |
s5s8_sequence_number_registry_count | Gauge | Respostas S5/S8 pendentes (aguardando resposta) |
sxb_peer_registry_count | Gauge | Número de processos de peer PFCP registrados |
Uso:
# Sessões ativas atuais
teid_registry_count
# Taxa de criação de sessões (por segundo)
rate(teid_registry_count[5m])
# Sessões máximas na última hora
max_over_time(teid_registry_count[1h])
Contadores de Mensagens
Mensagens S5/S8 (GTP-C):
| Nome da Métrica | Tipo | Rótulos | Descrição |
|---|---|---|---|
s5s8_inbound_messages_total | Counter | message_type | Total de mensagens S5/S8 recebidas |
s5s8_outbound_messages_total | Counter | message_type | Total de mensagens S5/S8 enviadas |
s5s8_inbound_errors_total | Counter | message_type | Erros de processamento S5/S8 |
Tipos de Mensagens:
create_session_requestcreate_session_responsedelete_session_requestdelete_session_responsecreate_bearer_requestdelete_bearer_request
Mensagens Sxb (PFCP):
| Nome da Métrica | Tipo | Rótulos | Descrição |
|---|---|---|---|
sxb_inbound_messages_total | Counter | message_type | Total de mensagens PFCP recebidas |
sxb_outbound_messages_total | Counter | message_type | Total de mensagens PFCP enviadas |
sxb_inbound_errors_total | Counter | message_type | Erros de processamento PFCP recebidos |
sxb_outbound_errors_total | Counter | message_type | Erros de processamento PFCP enviados |
Tipos de Mensagens:
association_setup_requestassociation_setup_responseheartbeat_requestheartbeat_responsesession_establishment_requestsession_establishment_responsesession_modification_requestsession_deletion_request
Mensagens Gx (Diameter):
| Nome da Métrica | Tipo | Rótulos | Descrição |
|---|---|---|---|
gx_inbound_messages_total | Counter | message_type | Total de mensagens Diameter recebidas |
gx_outbound_messages_total | Counter | message_type | Total de mensagens Diameter enviadas |
gx_inbound_errors_total | Counter | message_type | Erros de processamento Diameter recebidos |
gx_outbound_errors_total | Counter | message_type | Erros de processamento Diameter enviados |
gx_outbound_responses_total | Counter | message_type, result_code_class, diameter_host | Respostas Diameter enviadas, categorizadas por classe de código de resultado e host peer |
Tipos de Mensagens:
gx_CCA(Credit-Control-Answer)gx_CCR(Credit-Control-Request)gx_RAA(Re-Auth-Answer)gx_RAR(Re-Auth-Request)
Classes de Código de Resultado (para gx_outbound_responses_total):
2xxx- Respostas de sucesso (ex: 2001 DIAMETER_SUCCESS)3xxx- Erros de protocolo (ex: 3001 DIAMETER_COMMAND_UNSUPPORTED)4xxx- Falhas transitórias (ex: 4001 DIAMETER_AUTHENTICATION_REJECTED)5xxx- Falhas permanentes (ex: 5012 DIAMETER_UNABLE_TO_COMPLY)
Exemplos de Uso:
# Monitorar taxa de sucesso de respostas Gx
sum(rate(gx_outbound_responses_total{result_code_class="2xxx"}[5m])) /
sum(rate(gx_outbound_responses_total[5m])) * 100
# Rastrear falhas por host PCRF
rate(gx_outbound_responses_total{result_code_class!="2xxx"}[5m]) by (diameter_host)
# Contar total de mensagens Re-Auth-Answer bem-sucedidas
gx_outbound_responses_total{message_type="gx_RAA",result_code_class="2xxx"}
# Alertar sobre alta taxa de falhas para PCRF específico
rate(gx_outbound_responses_total{result_code_class=~"4xxx|5xxx",diameter_host="pcrf.example.com"}[5m]) > 0.1
Tratamento de Erros:
| Nome da Métrica | Tipo | Rótulos | Descrição |
|---|---|---|---|
rescues_total | Counter | module, function | Total de blocos de resgate atingidos (tratamento de exceções) |
Métricas de Latência
Duração do Processamento de Mensagens Recebidas:
| Nome da Métrica | Tipo | Rótulos | Descrição |
|---|---|---|---|
s5s8_inbound_handling_duration | Histogram | request_message_type | Tempo de manipulação de mensagens S5/S8 (inclui decodificação, codificação, envio, recebimento) |
sxb_inbound_handling_duration | Histogram | request_message_type | Tempo de manipulação de mensagens PFCP (inclui decodificação, codificação, envio, recebimento) |
gx_inbound_handling_duration | Histogram | request_message_type | Tempo de manipulação de mensagens Diameter (inclui decodificação, codificação, envio, recebimento) |
Duração de Transação de Saída:
| Nome da Métrica | Tipo | Rótulos | Descrição |
|---|---|---|---|
s5s8_outbound_transaction_duration | Histogram | request_message_type | Tempo de ida e volta de solicitação-resposta S5/S8 |
sxb_outbound_transaction_duration | Histogram | request_message_type | Tempo de ida e volta de solicitação-resposta PFCP (exclui codificação/decodificação) |
gx_outbound_transaction_duration | Histogram | request_message_type | Tempo de ida e volta de solicitação-resposta Diameter (inclui codificação/decodificação) |
Buckets (segundos):
- Valores: 0.0001, 0.0005, 0.001, 0.005, 0.01, 0.05, 0.1, 0.5, 1.0, 5.0
- (100µs, 500µs, 1ms, 5ms, 10ms, 50ms, 100ms, 500ms, 1s, 5s)
Uso:
# Latência S5/S8 do 95º percentil
histogram_quantile(0.95,
rate(s5s8_inbound_handling_duration_bucket[5m])
)
# Latência média PFCP
rate(sxb_inbound_handling_duration_sum[5m]) /
rate(sxb_inbound_handling_duration_count[5m])
Monitoramento de Saúde do UPF
Métricas de Peer UPF:
| Nome da Métrica | Tipo | Rótulos | Descrição |
|---|---|---|---|
upf_peers_total | Gauge | - | Total de peers UPF registrados |
upf_peers_healthy | Gauge | - | Número de peers UPF saudáveis (associados + batimentos de coração OK) |
upf_peers_unhealthy | Gauge | - | Número de peers UPF não saudáveis |
upf_peers_associated | Gauge | - | Número de peers UPF com associação PFCP ativa |
upf_peers_unassociated | Gauge | - | Número de peers UPF sem associação PFCP |
upf_peer_healthy | Gauge | peer_ip | Status de saúde de um UPF específico (1=saudável, 0=não saudável) |
upf_peer_missed_heartbeats | Gauge | peer_ip | Batimentos de coração consecutivos perdidos para um UPF específico |
Uso:
# Monitorar saúde do pool UPF
upf_peers_healthy / upf_peers_total
# Alertar sobre UPFs não saudáveis
upf_peers_unhealthy > 0
# Rastrear saúde de um UPF específico
upf_peer_healthy{peer_ip="10.98.0.20"}
# Identificar UPFs com problemas de batimento de coração
upf_peer_missed_heartbeats > 2
Exemplos de Alertas:
# Alertar quando UPF fica fora do ar
- alert: UPF_Peer_Down
expr: upf_peer_healthy == 0
for: 1m
labels:
severity: critical
annotations:
summary: "UPF {{ $labels.peer_ip }} está fora do ar"
description: "Peer UPF não respondendo aos batimentos de coração PFCP"
# Alertar quando múltiplos UPFs estão fora do ar
- alert: UPF_Pool_Degraded
expr: (upf_peers_healthy / upf_peers_total) < 0.5
for: 2m
labels:
severity: critical
annotations:
summary: "Pool UPF degradado"
description: "Apenas {{ $value | humanizePercentage }} dos UPFs estão saudáveis"
# Aviso sobre batimentos de coração perdidos
- alert: UPF_Heartbeat_Issues
expr: upf_peer_missed_heartbeats > 2
for: 30s
labels:
severity: warning
annotations:
summary: "UPF {{ $labels.peer_ip }} com problemas de batimento de coração"
description: "{{ $value }} batimentos de coração consecutivos perdidos"
Monitoramento de Saúde do P-CSCF
Métricas do Servidor P-CSCF:
| Nome da Métrica | Tipo | Rótulos | Descrição |
|---|---|---|---|
pcscf_fqdns_total | Gauge | - | Total de FQDNs P-CSCF sendo monitorados |
pcscf_fqdns_resolved | Gauge | - | FQDNs P-CSCF resolvidos com sucesso via DNS |
pcscf_fqdns_failed | Gauge | - | FQDNs P-CSCF que falharam na resolução DNS |
pcscf_servers_total | Gauge | - | Total de servidores P-CSCF descobertos |
pcscf_servers_healthy | Gauge | fqdn | Servidores P-CSCF saudáveis por FQDN |
pcscf_servers_unhealthy | Gauge | fqdn | Servidores P-CSCF não saudáveis por FQDN |
Veja: Guia de Monitoramento P-CSCF para rastreamento detalhado da saúde IMS.
Métricas de Licença
Status da Licença:
| Nome da Métrica | Tipo | Descrição |
|---|---|---|
license_status | Gauge | Status atual da licença (1 = válido, 0 = inválido) |
Uso:
# Verificar se a licença é válida
license_status == 1
# Alertar sobre licença inválida
license_status == 0
Exemplo de Alerta:
- alert: PGW_C_License_Invalid
expr: license_status == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Licença PGW-C inválida ou expirada"
description: "O status da licença é inválido - solicitações de criação de sessão estão sendo bloqueadas"
Impacto da Licença Inválida:
Quando a licença é inválida ou o servidor de licença não está acessível, Solicitações de Criação de Sessões serão rejeitadas com o código de causa GTP-C "Sem recursos disponíveis" (73). Isso é visível em capturas de pacotes como mostrado abaixo:
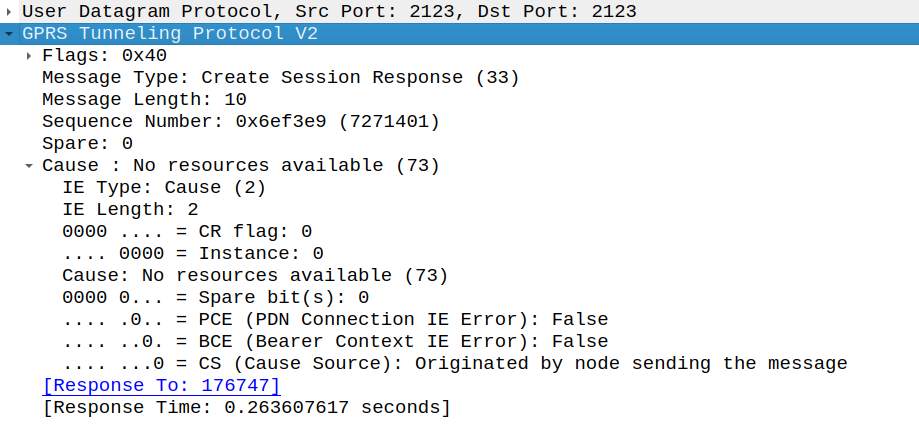
Captura do Wireshark mostrando Resposta de Criação de Sessão com causa "Sem recursos disponíveis" quando a licença é inválida
Notas:
- Nome do produto registrado com o servidor de licença:
omnipgwc - A URL do servidor de licença está configurada em
config/runtime.exssob:license_client - Quando a licença é inválida (
license_status == 0), solicitações de criação de sessão são bloqueadas com o código de causa GTP-C 73 (Sem recursos disponíveis) - A interface do usuário e o monitoramento permanecem acessíveis independentemente do status da licença
- Peers Diameter, GTP-C e PFCP continuam a manter conexões
- Sessões existentes não são afetadas - apenas a criação de novas sessões é bloqueada
Métricas do Sistema
Métricas do VM Erlang:
| Nome da Métrica | Tipo | Descrição |
|---|---|---|
vm_memory_total | Gauge | Memória total da VM (bytes) |
vm_memory_processes | Gauge | Memória usada pelos processos |
vm_memory_system | Gauge | Memória usada pelo sistema |
vm_system_process_count | Gauge | Total de processos Erlang |
vm_system_port_count | Gauge | Total de portas abertas |
Configuração do Prometheus
Configuração de Scrape
Adicione o OmniPGW ao prometheus.yml do Prometheus:
# prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'omnipgw'
static_configs:
- targets: ['10.0.0.20:9090']
labels:
instance: 'omnipgw-01'
environment: 'production'
site: 'datacenter-1'
Múltiplas Instâncias do OmniPGW
scrape_configs:
- job_name: 'omnipgw'
static_configs:
- targets:
- '10.0.0.20:9090'
- '10.0.0.21:9090'
- '10.0.0.22:9090'
labels:
environment: 'production'
Descoberta de Serviço
Kubernetes:
scrape_configs:
- job_name: 'omnipgw'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app]
action: keep
regex: omnipgw
- source_labels: [__meta_kubernetes_pod_ip]
target_label: __address__
replacement: '${1}:9090'
Verificação
Teste de scrape:
# Verificar alvos do Prometheus
curl http://prometheus:9090/api/v1/targets
# Consultar uma métrica
curl 'http://prometheus:9090/api/v1/query?query=teid_registry_count'
Painéis do Grafana
Configuração do Painel
1. Adicionar Fonte de Dados do Prometheus:
Configuração → Fontes de Dados → Adicionar fonte de dados → Prometheus
URL: http://prometheus:9090
2. Importar Painel:
Crie um novo painel ou importe de JSON.
Painéis Principais
Painel 1: Sessões Ativas
# Consulta
teid_registry_count
# Tipo de Painel: Gauge
# Limiares:
# Verde: < 5000
# Amarelo: 5000-8000
# Vermelho: > 8000
Painel 2: Taxa de Sessão
# Consulta
rate(s5s8_inbound_messages_total{message_type="create_session_request"}[5m])
# Tipo de Painel: Gráfico
# Unidade: solicitações/segundo
Painel 3: Utilização do Pool de IP
# Consulta (para sub-rede /24 com 254 IPs)
(address_registry_count / 254) * 100
# Tipo de Painel: Gauge
# Unidade: percentual (0-100)
# Limiares:
# Verde: < 70%
# Amarelo: 70-85%
# Vermelho: > 85%
Painel 4: Latência de Mensagem (95º Percentil)
# Consulta
histogram_quantile(0.95,
rate(s5s8_inbound_handling_duration_bucket{request_message_type="create_session_request"}[5m])
)
# Tipo de Painel: Gráfico
# Unidade: milissegundos
Painel 5: Taxa de Erros
# Consulta
rate(s5s8_inbound_errors_total[5m])
# Tipo de Painel: Gráfico
# Unidade: erros/segundo
# Limite de Alerta: > 0.1
Painel 6: Taxa de Sucesso de Respostas Gx
# Consulta: Calcular percentual de respostas Gx bem-sucedidas
sum(rate(gx_outbound_responses_total{result_code_class="2xxx"}[5m])) /
sum(rate(gx_outbound_responses_total[5m])) * 100
# Tipo de Painel: Gauge
# Unidade: percentual (0-100)
# Limiares:
# Verde: > 95%
# Amarelo: 90-95%
# Vermelho: < 90%
Alternativa - Divisão por Classe de Código de Resultado:
# Consulta: Mostrar contagens de respostas por classe de código de resultado
sum(rate(gx_outbound_responses_total[5m])) by (result_code_class)
# Tipo de Painel: Gráfico de Pizza ou Gráfico de Barras
# Legenda: {{ result_code_class }}
Alternativa - Status de Resposta por PCRF:
# Consulta: Mostrar respostas por host PCRF
sum(rate(gx_outbound_responses_total[5m])) by (diameter_host, result_code_class)
# Tipo de Painel: Gráfico de Barras Empilhadas
# Legenda: {{ diameter_host }} - {{ result_code_class }}
Painel 7: Status de Saúde do UPF
# Consulta: Percentual geral de saúde do pool
(upf_peers_healthy / upf_peers_total) * 100
# Tipo de Painel: Gauge
# Unidade: percentual (0-100)
# Limiares:
# Verde: 100%
# Amarelo: 50-99%
# Vermelho: < 50%
Alternativa - Status por UPF:
# Consulta: Saúde individual do UPF
upf_peer_healthy
# Tipo de Painel: Estatística
# Mapeamentos:
# 1 = "UP" (Verde)
# 0 = "DOWN" (Vermelho)
Exemplo Completo de Painel
{
"dashboard": {
"title": "OmniPGW - Painel de Operações",
"panels": [
{
"title": "Sessões Ativas",
"targets": [
{
"expr": "teid_registry_count",
"legendFormat": "Sessões Ativas"
}
],
"type": "graph"
},
{
"title": "Taxa de Criação de Sessões",
"targets": [
{
"expr": "rate(s5s8_inbound_messages_total{message_type=\"create_session_request\"}[5m])",
"legendFormat": "Sessões/segundo"
}
],
"type": "graph"
},
{
"title": "Utilização do Pool de IP",
"targets": [
{
"expr": "(address_registry_count / 254) * 100",
"legendFormat": "Uso do Pool %"
}
],
"type": "gauge"
},
{
"title": "Latência de Mensagem (p95)",
"targets": [
{
"expr": "histogram_quantile(0.95, rate(s5s8_inbound_handling_duration_bucket[5m]))",
"legendFormat": "S5/S8 p95"
},
{
"expr": "histogram_quantile(0.95, rate(sxb_inbound_handling_duration_bucket[5m]))",
"legendFormat": "PFCP p95"
}
],
"type": "graph"
}
]
}
}
Alertas
Regras de Alerta
Crie omnipgw_alerts.yml:
groups:
- name: omnipgw
interval: 30s
rules:
# Alertas de Contagem de Sessões
- alert: OmniPGW_HighSessionCount
expr: teid_registry_count > 8000
for: 5m
labels:
severity: warning
annotations:
summary: "Contagem de sessões alta no OmniPGW"
description: "{{ $value }} sessões ativas (limite: 8000)"
- alert: OmniPGW_SessionCountCritical
expr: teid_registry_count > 9500
for: 2m
labels:
severity: critical
annotations:
summary: "Contagem de sessões crítica no OmniPGW"
description: "{{ $value }} sessões ativas se aproximando da capacidade"
# Alertas de Pool de IP
- alert: OmniPGW_IPPoolUtilizationHigh
expr: (address_registry_count / 254) * 100 > 80
for: 10m
labels:
severity: warning
annotations:
summary: "Utilização alta do pool de IP no OmniPGW"
description: "Pool de IP {{ $value }}% utilizado"
- alert: OmniPGW_IPPoolExhausted
expr: address_registry_count >= 254
for: 1m
labels:
severity: critical
annotations:
summary: "Pool de IP esgotado no OmniPGW"
description: "Nenhum IP disponível para alocação"
# Alertas de Taxa de Erros
- alert: OmniPGW_HighErrorRate
expr: rate(s5s8_inbound_errors_total[5m]) > 0.1
for: 5m
labels:
severity: warning
annotations:
summary: "Alta taxa de erros no OmniPGW"
description: "{{ $value }} erros/segundo na interface S5/S8"
- alert: OmniPGW_GxErrorRate
expr: rate(gx_inbound_errors_total[5m]) > 0.05
for: 5m
labels:
severity: warning
annotations:
summary: "Erros Gx no OmniPGW"
description: "{{ $value }} erros Diameter/segundo"
# Alertas de Respostas Gx
- alert: OmniPGW_GxResponseFailureRate
expr: |
sum(rate(gx_outbound_responses_total{result_code_class!="2xxx"}[5m])) /
sum(rate(gx_outbound_responses_total[5m])) > 0.1
for: 5m
labels:
severity: warning
annotations:
summary: "Alta taxa de falhas de resposta Gx no OmniPGW"
description: "{{ $value | humanizePercentage }} das respostas Gx são falhas (códigos de resultado não-2xxx)"
- alert: OmniPGW_GxPCRFFailures
expr: rate(gx_outbound_responses_total{result_code_class=~"4xxx|5xxx"}[5m]) by (diameter_host) > 0.05
for: 3m
labels:
severity: warning
annotations:
summary: "PCRF {{ $labels.diameter_host }} recebendo respostas de falha"
description: "{{ $value }} respostas de falha/segundo para PCRF {{ $labels.diameter_host }}"
# Alertas de Saúde do UPF
- alert: OmniPGW_UPF_PeerDown
expr: upf_peer_healthy == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Peer UPF {{ $labels.peer_ip }} fora do ar"
description: "UPF não respondendo aos batimentos de coração PFCP"
- alert: OmniPGW_UPF_PoolDegraded
expr: (upf_peers_healthy / upf_peers_total) < 0.5
for: 2m
labels:
severity: critical
annotations:
summary: "Pool UPF degradado"
description: "{{ $value | humanizePercentage }} dos UPFs estão saudáveis (< 50%)"
- alert: OmniPGW_UPF_HeartbeatFailures
expr: upf_peer_missed_heartbeats > 2
for: 30s
labels:
severity: warning
annotations:
summary: "UPF {{ $labels.peer_ip }} falhas de batimento de coração"
description: "{{ $value }} batimentos de coração consecutivos perdidos"
- alert: OmniPGW_UPF_AllDown
expr: upf_peers_healthy == 0 and upf_peers_total > 0
for: 30s
labels:
severity: critical
annotations:
summary: "Todos os peers UPF fora do ar"
description: "Nenhum UPF saudável disponível para criação de sessão"
# Alertas de Latência
- alert: OmniPGW_HighLatency
expr: |
histogram_quantile(0.95,
rate(s5s8_inbound_handling_duration_bucket[5m])
) > 100000
for: 5m
labels:
severity: warning
annotations:
summary: "Alta latência de mensagem no OmniPGW"
description: "Latência p95 {{ $value }}µs (> 100ms)"
# Alertas do Sistema
- alert: OmniPGW_HighMemoryUsage
expr: vm_memory_total > 2000000000
for: 10m
labels:
severity: warning
annotations:
summary: "Alta utilização de memória no OmniPGW"
description: "VM utilizando {{ $value | humanize }}B de memória"
- alert: OmniPGW_HighProcessCount
expr: vm_system_process_count > 100000
for: 10m
labels:
severity: warning
annotations:
summary: "Alta contagem de processos no OmniPGW"
description: "{{ $value }} processos Erlang (possível vazamento)"
Configuração do AlertManager
# alertmanager.yml
global:
resolve_timeout: 5m
route:
receiver: 'ops-team'
group_by: ['alertname', 'instance']
group_wait: 10s
group_interval: 10s
repeat_interval: 12h
routes:
- match:
severity: critical
receiver: 'pagerduty'
- match:
severity: warning
receiver: 'slack'
receivers:
- name: 'ops-team'
email_configs:
- to: 'ops@example.com'
- name: 'slack'
slack_configs:
- api_url: 'https://hooks.slack.com/services/YOUR/SLACK/WEBHOOK'
channel: '#omnipgw-alerts'
title: 'Alerta OmniPGW: {{ .GroupLabels.alertname }}'
text: '{{ range .Alerts }}{{ .Annotations.description }}{{ end }}'
- name: 'pagerduty'
pagerduty_configs:
- service_key: 'YOUR_PAGERDUTY_KEY'
Monitoramento de Performance
Indicadores-Chave de Performance (KPIs)
Consultas de Throughput
Taxa de Configuração de Sessão:
rate(s5s8_inbound_messages_total{message_type="create_session_request"}[5m])
Taxa de Destruição de Sessão:
rate(s5s8_inbound_messages_total{message_type="delete_session_request"}[5m])
Crescimento Líquido de Sessões:
rate(s5s8_inbound_messages_total{message_type="create_session_request"}[5m]) -
rate(s5s8_inbound_messages_total{message_type="delete_session_request"}[5m])
Análise de Latência
Latência de Processamento de Mensagens (Percentis):
# p50 (Mediana)
histogram_quantile(0.50,
rate(s5s8_inbound_handling_duration_bucket[5m])
)
# p95
histogram_quantile(0.95,
rate(s5s8_inbound_handling_duration_bucket[5m])
)
# p99
histogram_quantile(0.99,
rate(s5s8_inbound_handling_duration_bucket[5m])
)
Divisão de Latência por Tipo de Mensagem:
histogram_quantile(0.95,
rate(s5s8_inbound_handling_duration_bucket[5m])
) by (request_message_type)
Tendência de Capacidade
Tendência de Crescimento de Sessões (24h):
teid_registry_count -
teid_registry_count offset 24h
Capacidade Restante:
# Para capacidade máxima de 10.000 sessões
10000 - teid_registry_count
Tempo até o Esgotamento da Capacidade:
# Dias até a capacidade esgotada (com base na taxa de crescimento de 1h)
(10000 - teid_registry_count) /
(rate(teid_registry_count[1h]) * 86400)
Solução de Problemas com Métricas
Identificando Problemas
Problema: Alta Taxa de Rejeição de Sessões
Consulta:
rate(s5s8_inbound_errors_total[5m]) by (message_type)
Ação:
- Verifique os logs de erro
- Verifique a conectividade do PCRF (erros Gx)
- Verifique o esgotamento do pool de IP
Problema: Configuração de Sessão Lenta
Consulta:
histogram_quantile(0.95,
rate(s5s8_inbound_handling_duration_bucket{request_message_type="create_session_request"}[5m])
)
Ação:
- Verifique a latência Gx (tempo de resposta do PCRF)
- Verifique a latência PFCP (tempo de resposta do PGW-U)
- Revise o uso de recursos do sistema
Problema: Falhas de Política do PCRF
Consultas:
# Taxa geral de falhas de resposta Gx
sum(rate(gx_outbound_responses_total{result_code_class!="2xxx"}[5m])) /
sum(rate(gx_outbound_responses_total[5m])) * 100
# Divisão por host PCRF
sum(rate(gx_outbound_responses_total[5m])) by (diameter_host, result_code_class)
# Classes de código de resultado específicas
rate(gx_outbound_responses_total{result_code_class="5xxx"}[5m]) by (diameter_host)
Ação:
- Verifique a conectividade e saúde do PCRF
- Revise os perfis de assinantes no PCRF (erros 5xxx geralmente indicam problemas de política)
- Verifique a configuração do peer Diameter
- Verifique os logs do PCRF para erros correspondentes
- Para 5012 (DIAMETER_UNABLE_TO_COMPLY), revise o manuseio de Re-Auth-Request
Problema: Vazamento de Memória Suspeito
Consultas:
# Tendência de memória total
rate(vm_memory_total[1h])
# Tendência de memória do processo
rate(vm_memory_processes[1h])
# Tendência de contagem de processos
rate(vm_system_process_count[1h])
Ação:
- Verifique se há sessões obsoletas
- Revise as contagens de registro
- Reinicie se o vazamento for confirmado
Consultas de Depuração
Encontrar Hora de Pico de Sessão:
max_over_time(teid_registry_count[24h])
Comparar Atual vs. Histórico:
teid_registry_count /
avg_over_time(teid_registry_count[7d])
Identificar Anomalias:
abs(
teid_registry_count -
avg_over_time(teid_registry_count[1h])
) > 100
Melhores Práticas
Coleta de Métricas
- Intervalo de Scrape: 15-30 segundos (equilibrar granularidade vs. carga)
- Retenção: 15+ dias para análise histórica
- Rótulos: Use rotulagem consistente (instância, ambiente, site)
Design de Painéis
- Painel de Visão Geral - KPIs de alto nível para NOC
- Painéis Detalhados - Análise profunda por interface
- Painel de Solução de Problemas - Métricas de erro e logs
Design de Alertas
- Evitar Fadiga de Alertas - Alertar apenas sobre problemas acionáveis
- Escalonamento - Aviso → Crítico com gravidade crescente
- Contexto - Incluir links de runbook nas descrições de alerta
Documentação Relacionada
Configuração e Configuração
- Guia de Configuração - Configuração de métricas do Prometheus, configuração da Interface Web
- Guia de Solução de Problemas - Usando métricas para depuração
Métricas de Interface
- Interface PFCP - Métricas de sessão PFCP, monitoramento de saúde do UPF
- Interface Diameter Gx - Métricas de política Gx, rastreamento de interação com PCRF
- Interface Diameter Gy - Métricas de cobrança Gy, rastreamento de cotas, timeouts de OCS
- Interface S5/S8 - Métricas de mensagens GTP-C, comunicação SGW-C
Monitoramento Especializado
- Monitoramento P-CSCF - Métricas de descoberta P-CSCF, saúde IMS
- Gerenciamento de Sessões - Sessões ativas, métricas do ciclo de vida da sessão
- Alocação de IP de UE - Métricas de utilização do pool de IP
Guia de Monitoramento do OmniPGW - por Omnitouch Network Services